Basic Concept of Machine Code Analysis
This chapter gives an overview on the basic concepts of Machine Code Analysis as integrated into EcoStruxure Machine Expert.
Software Components of Machine Code Analysis
The diagram gives an overview of the high-level software components of Machine Code Analysis:
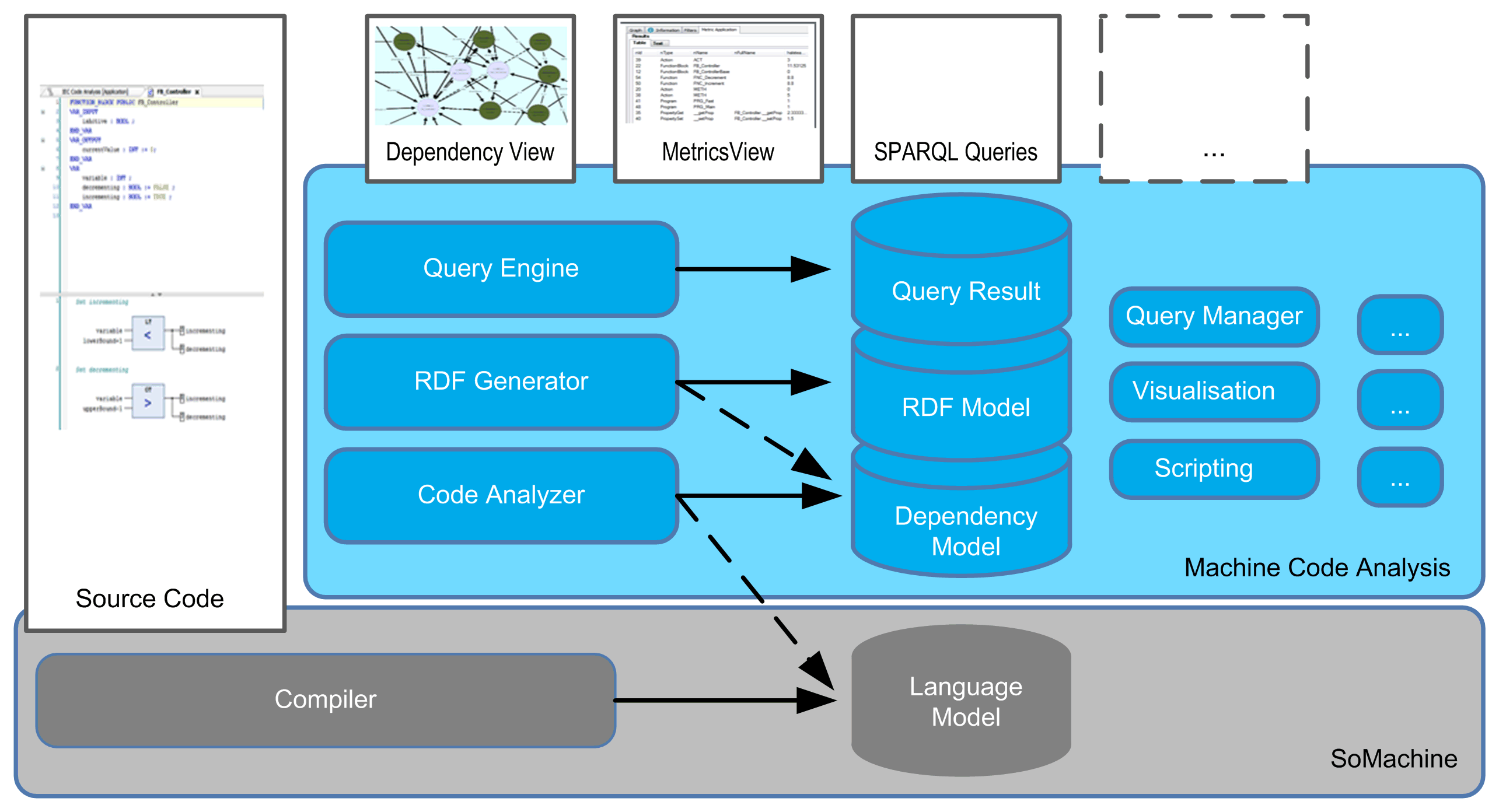
The components can be categorized into three different types:
oUI components displaying data:
oEditors to write the source code.
oEditors to visualize the results like metrics or conventions, or a graphical representation of the source code structure.
oData models as input or output of other components:
oLanguage model
oDependency model
oRDF model
oQuery results
oComponents transforming data:
oThe source code compiler (with language model as output) processes the source code to check the syntax and build the language model to generate the executable code running on controllers.
oThe source code analyzer (with dependency model as output) analyzes the language model and transforms it into a dependency model (and keeps it up-to-date).
oThe RDF model generator (with RDF model as output) transforms the dependency model into an RDF model to build the bridge to the semantic Web technologies.
oThe Query execution engine (with query results as output) executes SPARQL queries on the RDF model to get the query results.
Analysis Data (Dependency Model) Concept
The application is analyzed and a dependency model is built.
The dependency model is a list of nodes connected via edges.
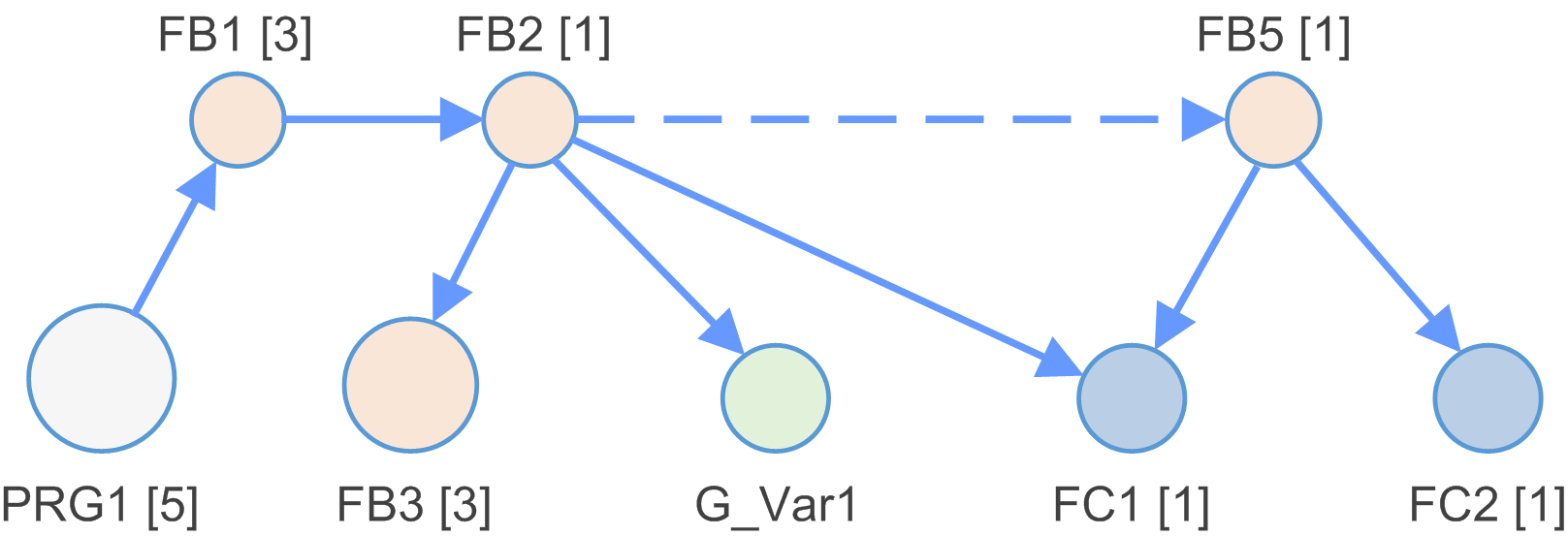
Examples of node types:
|
Node type |
Description |
|---|---|
|
Function block |
Function block (FB) inside the dependency model. Created for every function block added to the EcoStruxure Machine Expert project. |
|
Program |
Progam (PRG) inside the dependency model. Created for every program added to the EcoStruxure Machine Expert project. |
|
Function |
Function (FC) inside the dependency model. Created for every function added to the EcoStruxure Machine Expert project. |
|
... |
... |
Examples of edge types:
|
Edge type |
Description |
|---|---|
|
Read |
Read operation from code as source to a variable node as target. |
|
Write |
Write operation from code as source to a variable node as target. |
|
Call |
Call of a function block, method, action, program, and so on, from the code as source to a target node. |
|
Extend |
Extension of a basis type. For example, FB extension by another function block. |
|
... |
... |
One of the most important components of code analysis is the source code analyzer which transforms the language model into a dependency model (the analysis data).
This source code analyzer is based on a concept called analysis stages. This is used to optimize usability and performance (from memory and CPU point of view).
Example:
oTo get the extend and implement dependencies is a fast code analysis operation and needs less time compared to call, read or write dependencies.
oTo get the list of the function blocks and the extend and implement dependencies, it is sufficient to stop analysis at a specific analysis depth.
oIf more details are required, the analysis depth must be increased for specific elements (for example, to visualize some function blocks in the dependency view), or maybe for the objects in the project (for example to get metrics results).
Five analysis stages are available:
oStage 1: Create main nodes (for example, function blocks).
oStage 2: Link main nodes via edges.
oStage 3: Create sub nodes (for example, variables).
oStage 4: Link sub nodes via edges.
oStage 5: Calculate metrics.
User-relevant analysis stages:
Three approaches are relevant:
oMinimum analysis depth (stage 1+2): The content visible in the project and the EcoStruxure Machine Expert navigators.
oFBs, PRGs, FCs, DUTs, and so on
oProperties and their get / set methods
oMethods
oActions
oStructural information (folder, and so on)
oLibrary references
This analysis depth needs the least time.
oIntermediate analysis depth (stage 3+4): Next level of information from source code.
For example:
oVariables
oRead of variable dependencies
oWrite of variable dependencies
oCall of methods, functions, function blocks, programs, and so on
This analysis depth needs much time.
oMaximum analysis depth (stage 5): Metric information based on implementation (the source code).
For example:
oHalstead Complexity
oLines Of Code (LOC)
o...
This analysis depth needs the most time. (Only for metrics or conventions).
The open and flexible code analysis feature is based on semantic Web technologies. Some of these technologies are:
oResource Description Framework (RDF) - RDF Model
Refer to https://en.wikipedia.org/wiki/Resource_Description_Framework.
oRDF Database (Semantic Web Database) - an RDF Triple Storage
Refer to https://en.wikipedia.org/wiki/Triplestore
oSPARQL Protocol and RDF Query Language - SPARQL.
Refer to https://en.wikipedia.org/wiki/SPARQL.
Dependency Model to RDF Model Synchronization
The dependency model is the result of a code analysis run.
To link up to an open, flexible code analysis feature with query language support, the dependency model is synchronized with an RDF model.
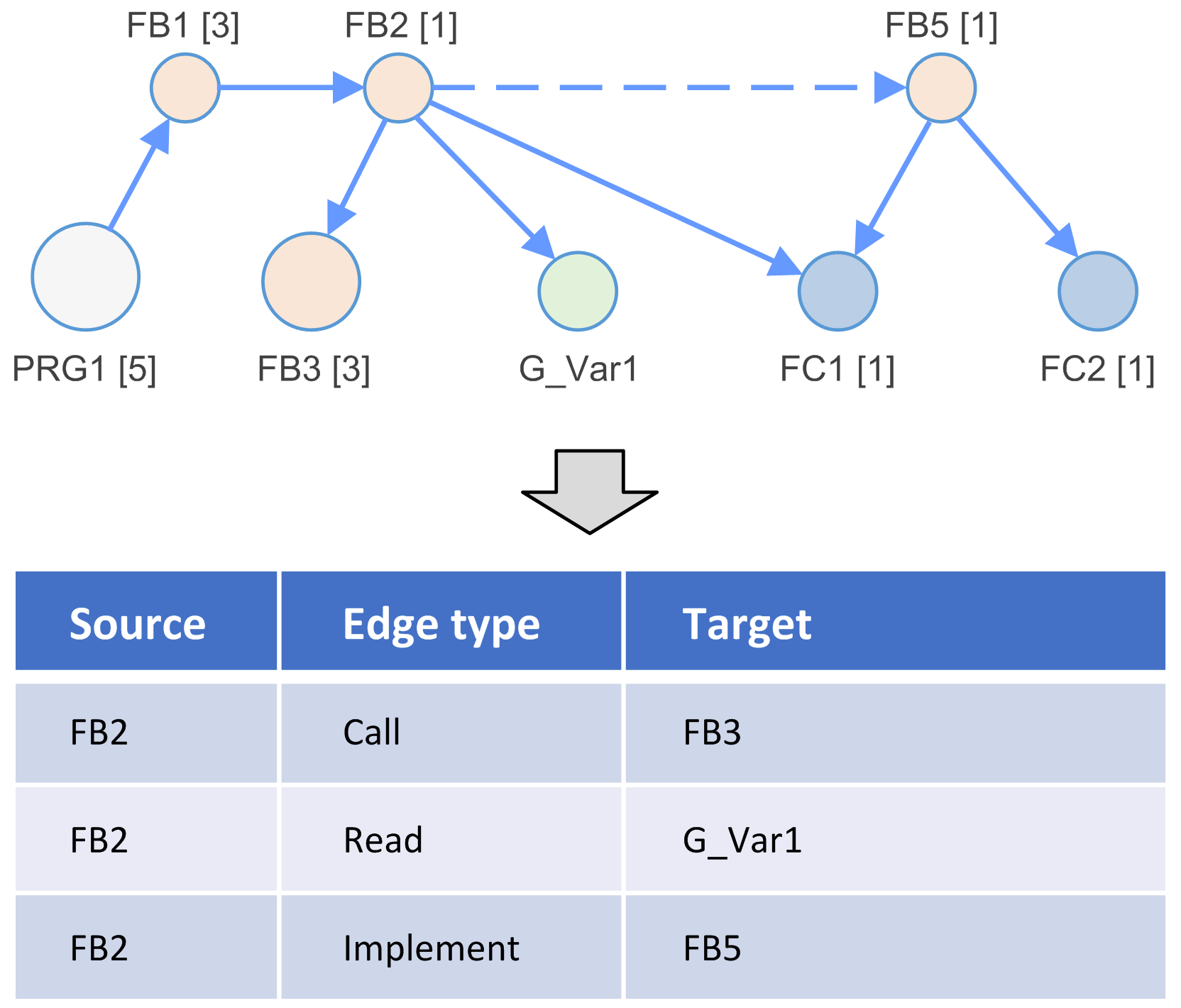
To support the analysis of large projects, the RDF model is kept in a separate process called RDF Triple Storage.
By default, the RDF Triple Storage is used. If required, the behavior can be configured in the Code Analysis Manager.
Resource Description Framework (RDF) is a data model for describing resources and the relations between these resources.
Example:
|
:(Subject) |
:(Predicate) |
:(Object) |
|---|---|---|
|
:Car |
:Weights |
:1000 kg |
|
:Car |
:ConsistsOf |
:Wheels |
|
:Car |
:ConsistsOf |
:Engine |
SPARQL is an acronym for Sparql Protocol and RDF Query Language. The SPARQL specification (https://www.w3.org/TR/sparql11-overview/) provides languages and protocols to query and manipulate RDF graphs - similar to SQL queries.
Example of s simple SPARQL query to get the node Ids and their names of the function blocks of an RDF model:
SELECT ?NodeId ?Name
WHERE {
# Select all FunctionBlocks and their names
?NodeId a :FunctionBlock ;
:Name ?Name .
}